Research
My research spans video understanding, explainable AI, temporal modeling, and geometry-aware generation. A common theme across these projects is building models that are not only effective, but also more interpretable, structured, or physically consistent.
Overview
- Research areas: video understanding, explainable AI, temporal modeling, and geometry-aware generation
- Common thread: interpretable or structured representations for vision models
- Outputs: publications, open-source code, datasets, and visual demonstrations
Satellite-to-Street-View Video Generation
Contributed to a research series on generating street-view video from satellite imagery and target trajectories. These works explored geometry-aware generation through voxel-based and point-cloud-based intermediate scene representations, improving photorealism and frame-to-frame continuity.
Sat2Vid: Street-view video synthesis from a single satellite image
Sat2Scene: 3D urban scene generation from satellite images with diffusion
Focus
- Geometry-aware street-view video synthesis from satellite imagery
- 3D scene representations for temporal consistency
- Collaborative contribution across method design, preprocessing, and baseline implementation
Links
- Sat2Vid paper: Sat2Vid: Street-view Panoramic Video Synthesis from a Single Satellite Image
- Sat2Scene paper: Sat2Scene: 3D Urban Scene Generation from Satellite Images with Diffusion
- Sat2Scene project: Sat2Scene
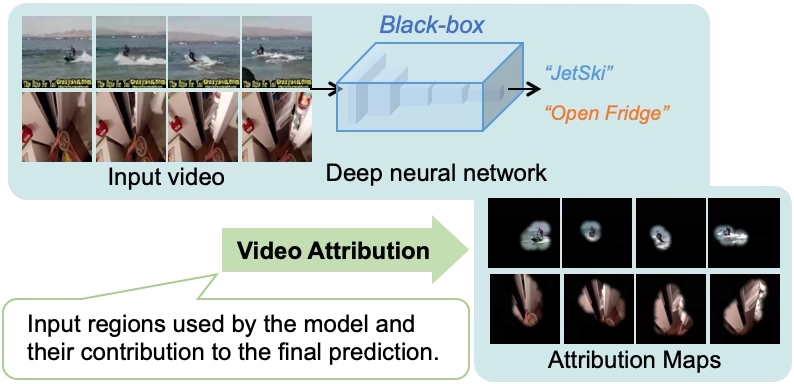
Model-Agnostic Visual Explanation for Video Understanding
Proposed a model-agnostic method for visually explaining video-understanding networks by identifying the spatial-temporal regions most responsible for a model’s prediction. Extended the work with a more detailed and objective evaluation framework for explanation methods.
 |
 |
 |
 |
 |
 |
Focus
- Model-agnostic explanation for video models
- Spatiotemporal saliency and continuity
- Objective evaluation metrics for explanation quality
Links
- WACV 2021 paper: Visually Explaining Video Understanding Networks with Perturbation
- TCSVT 2022 paper: Evaluation Metrics of Visual Explanation Methods
- Code: GitHub repository
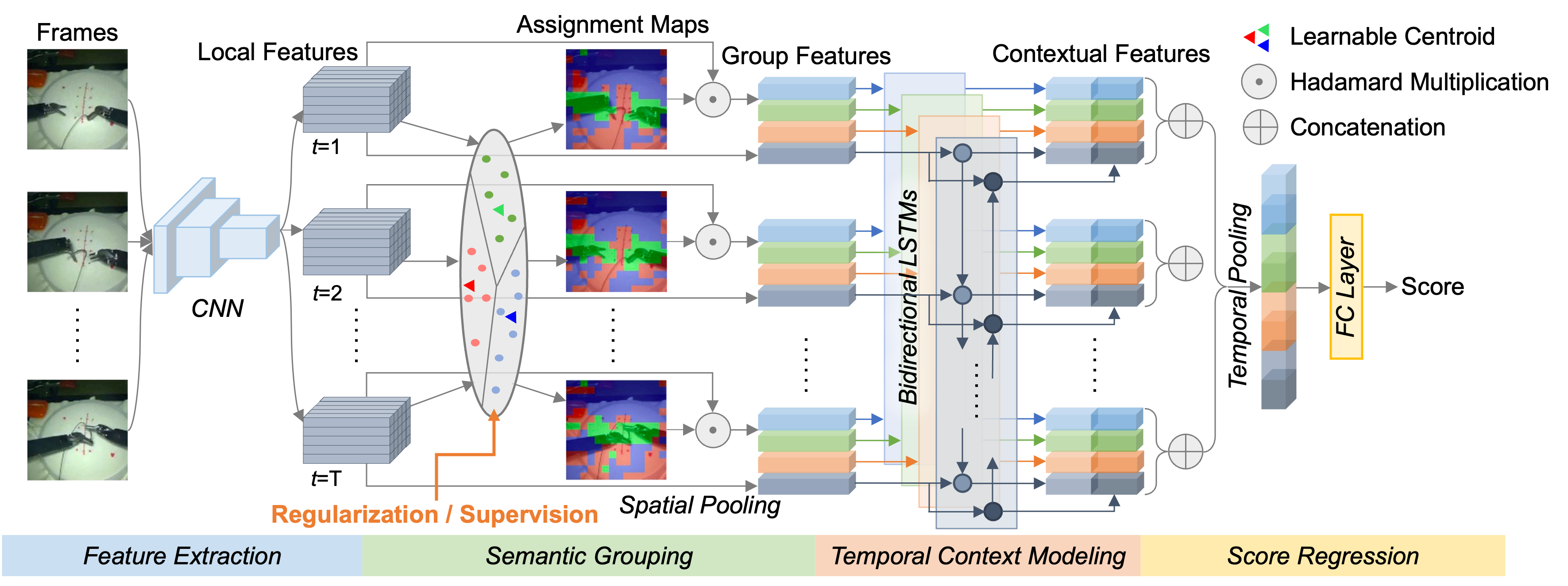
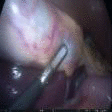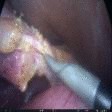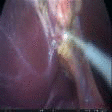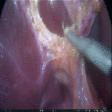
Surgical Skill Assessment via Video Semantic Aggregation
Developed an interpretable video model for assessing da Vinci robotic surgery skill. The method clusters visual features into semantic abstractions before temporal modeling, improving both transparency and benchmark accuracy.
 |
 |
 |
 |
 |
 |
Focus
- Video-based robotic surgical skill assessment
- Semantic aggregation of spatiotemporal features
- Transparent intermediate representations for analysis and supervision
Links
- MICCAI 2022 paper: Surgical Skill Assessment via Video Semantic Aggregation
- Code: GitHub repository
Video Skill Assessment with Attention-Based RNN
Proposed an attention-based recurrent model for video-based skill assessment and built a new dataset for the task. The method improved over prior approaches and produced per-frame attention maps for interpretability.
 |
> |  |
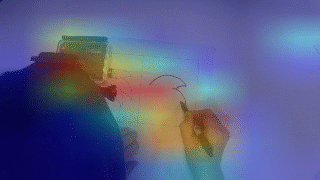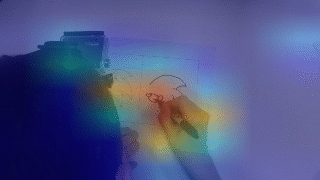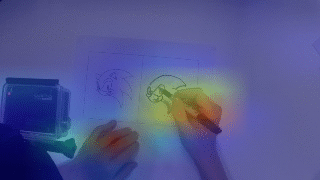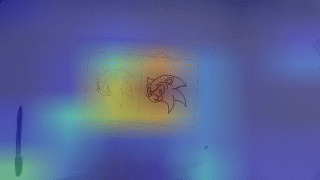 |
> |  |
Focus
- Skill score regression from video
- Spatial attention for interpretability
- Dataset construction for a new task
Links
- ICCV 2019 EPIC Workshop paper: Video-based skill assessment with spatial attention network
- Code: GitHub repository